

这篇文章主要是分享一下如何开发一个淘宝的Python爬虫,用来批量爬取商品用户评论。
在这个过程中呢,又碰到了之前在闲鱼遇到过的那位”老朋友”——sign参数。毕竟这俩平台属于同一个集团,同种同源也很正常。
但说实话,分析下来还是有点意外的。这个sign加密参数给我的感觉是——它的主要目的好像不是防爬虫,更像是防止参数被随意篡改。更意外的是,它居然就是一个连盐都没加的MD5,这个确实没想到。
因为之前写过一篇《闲鱼sign参数加密分析与本地复现》,里面已经把找sign参数的整个过程讲得比较详细了,所以这篇关于怎么定位加密位置的部分就不重复赘述了,直接开干。

一、抓包定位:搜索特征快速锁定加密位置
先在淘宝随便打开一个商品页面,然后打开开发者工具,刷新一下抓包。
因为有了上次咸鱼的经验,知道sign拼接的时候有个明显的特征——token + "&"。所以直接在全局搜一下token+"&",很快就能定位到加密参数生成的位置。搜出来一共3个结果,全部打上断点。
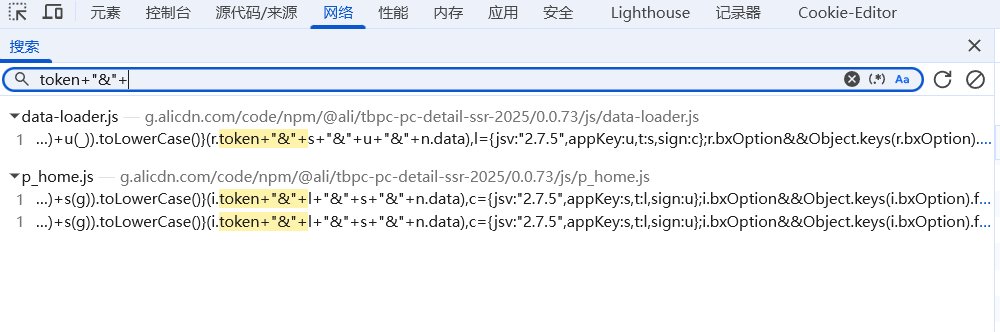
二、断点调试:找到sign生成逻辑
然后点一下商品的”查看评论”,断点就触发了。
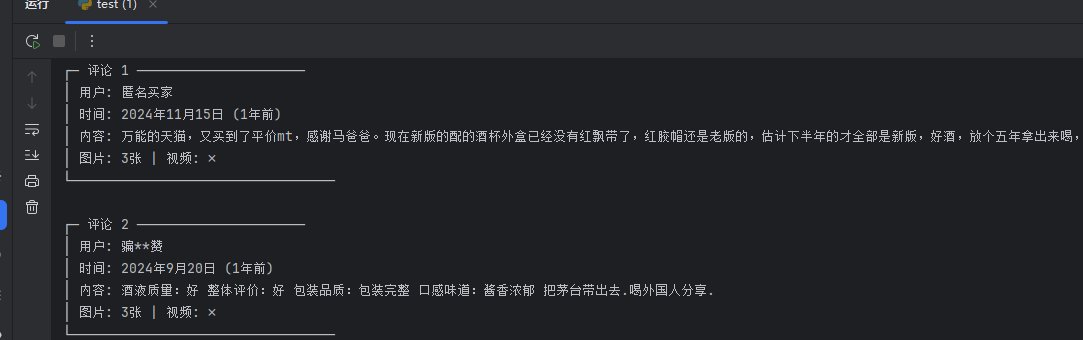
断点放行继续往下走,就能看到一条请求 /h5/mtop.taobao.rate.detaillist.get/6.0/ 的数据包。点开预览,里面的 rateList 数组存放的就是用户评论数据,也就是我们这次Python爬虫要采集的目标。
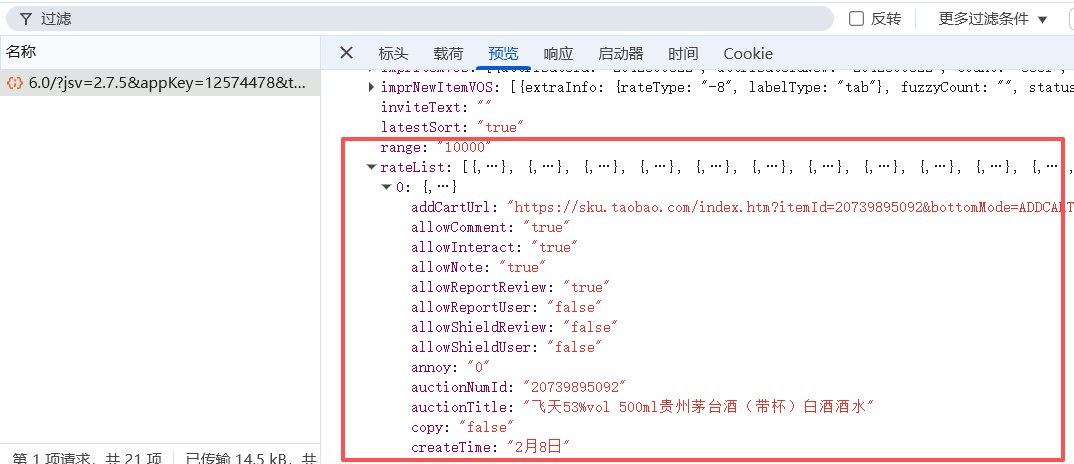
再切换到”载荷”页面看一下,这个接口的查询字符串参数:
params = {
"jsv": "2.7.5",
"appKey": "12574478",
"t": "1781669844366",
"sign": "9cf8c80fc6163a2f7505d0968ac139b9",
"_bx-login": "new",
"api": "mtop.taobao.rate.detaillist.get",
"v": "6.0",
"isSec": "0",
"ecode": "1",
"timeout": "20000",
"dataType": "jsonp",
"valueType": "string",
"type": "jsonp",
"callback": "mtopjsonp1781669844366",
"data": "{"showTrueCount":false,"auctionNumId":"20739895092","pageNo":1,"pageSize":20,"orderType":"","searchImpr":"-8","expression":"","skuVids":"","rateSrc":"pc_rate_list","rateType":"","foldFlag":"0"}"
}可以看到,这个接口只有sign这一个加密参数,其他都是明文。
三、算法分析:确认标准MD5
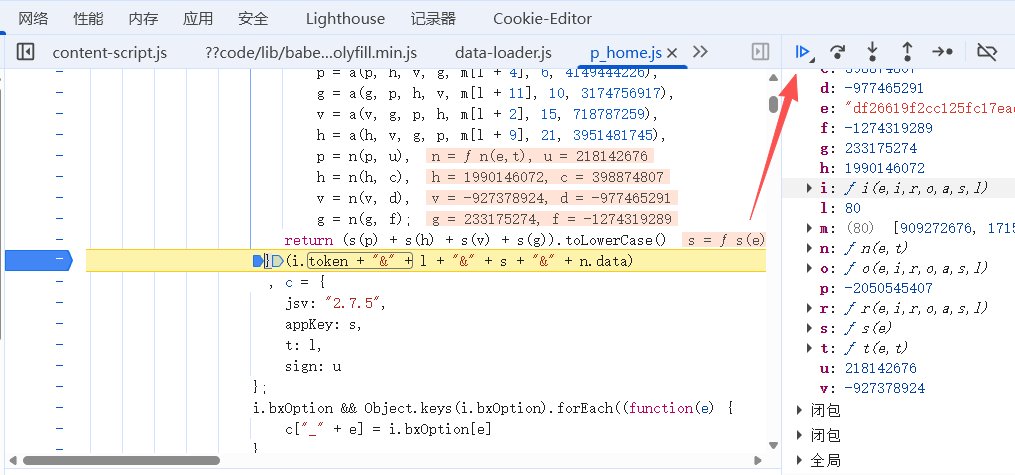
继续触发断点,看看sign到底是怎么生成的。断下来之后可以看到,sign是由一个自执行函数u生成的:
, u = function(e) {
// 省略中间代码
p = 1732584193,
h = 4023233417,
v = 2562383102,
g = 271733878,
return (s(p) + s(h) + s(v) + s(g)).toLowerCase()
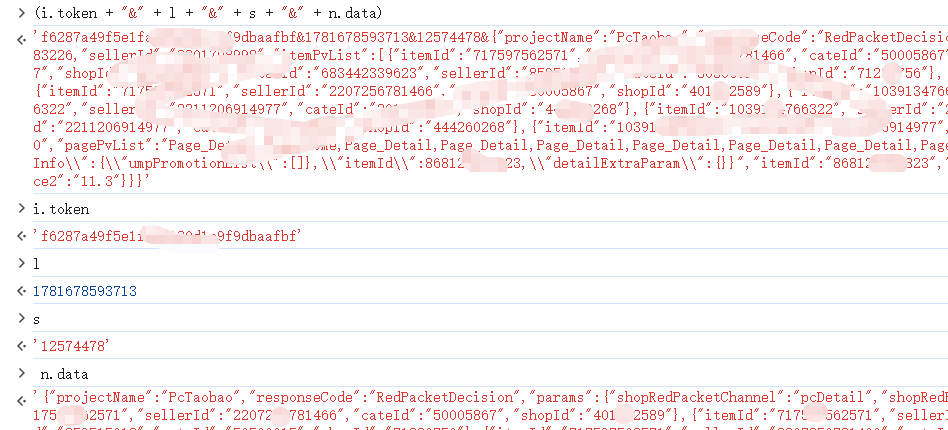
}(i.token + "&" + l + "&" + s + "&" + n.data)关键信息在这里:i.token + "&" + l + "&" + s + "&" + n.data就是生成sign所需的拼接字符串,而p, h, v, g这四个数字,分别是:
1732584193
4023233417
2562383102
271733878稍微熟悉哈希算法的朋友应该一眼就能认出来,这是MD5固定的初始向量。
所以结论很明显了:这就是标准MD5,没有加盐,没有魔改。

四、Python复现:封装签名生成函数
既然只是标准MD5,那完全不用扣JS代码了,直接用Python的hashlib写个函数:
import hashlib
def generate_sign(token, timestamp, app_key, data):
sign_str = f"{token}&{timestamp}&{app_key}&{data}"
sign = hashlib.md5(sign_str.encode('utf-8')).hexdigest()
return sign参数来源:
- token:从cookie的
_m_h5_tk中提取 - timestamp:当前毫秒级时间戳
- app_key:固定值
12574478 - data:请求体的JSON字符串(紧凑格式)
在控制台打印各参数验证一下:
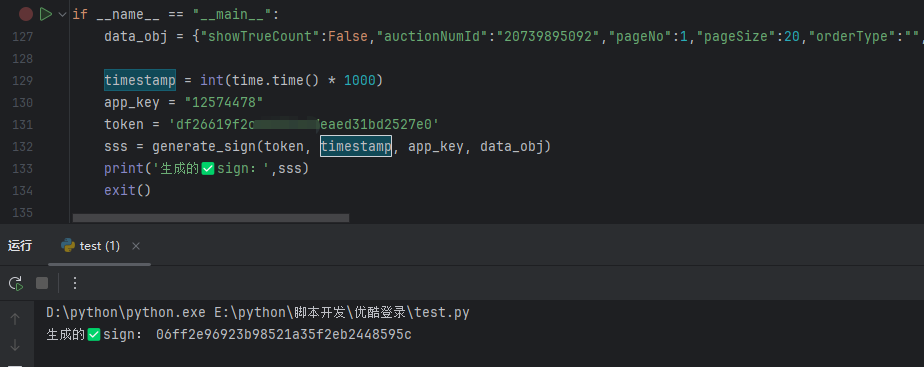
五、完整流程:从商品ID到评论数据
封装请求函数:
def build_rate_request(auction_num_id, token, page_no=1, page_size=20, rate_type=""):
timestamp = int(time.time() * 1000)
app_key = "12574478"
data_obj = {
"showTrueCount": False,
"auctionNumId": str(auction_num_id),
"pageNo": page_no,
"pageSize": page_size,
"orderType": "",
"searchImpr": "",
"expression": "",
"skuVids": "",
"rateSrc": "pc_rate_list",
"rateType": rate_type,
"foldFlag": "0"
}
data_str = json.dumps(data_obj, separators=(',', ':'))
sign = generate_sign(token, timestamp, app_key, data_str)
url = (
f"https://h5api.m.tmall.com/h5/mtop.taobao.rate.detaillist.get/6.0/"
f"?jsv=2.7.5&appKey={app_key}&t={timestamp}&sign={sign}"
f"&_bx-login=new&api=mtop.taobao.rate.detaillist.get&v=6.0"
f"&isSec=0&ecode=1&timeout=20000&dataType=jsonp&valueType=string"
f"&type=jsonp&callback=mtopjsonp{timestamp}&data={quote(data_str)}"
)
return url采集函数:
def fetch_rates(auction_num_id, cookie_string, page_no=1, page_size=20):
token = get_token_from_cookie(cookie_string)
if not token:
print(" 未找到token")
return []
url = build_rate_request(auction_num_id, token, page_no, page_size)
cookies = {}
for item in cookie_string.split(';'):
item = item.strip()
if '=' in item:
k, v = item.split('=', 1)
cookies[k] = v
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'referer': 'https://detail.tmall.com/'
}
response = requests.get(url, headers=headers, cookies=cookies, timeout=30)
if response.status_code != 200:
print(f" 请求失败: {response.status_code}")
return []
content = response.text
start = content.find('(')
end = content.rfind(')')
if start == -1 or end == -1:
print(" 解析失败")
return []
json_str = content[start + 1:end]
data = json.loads(json_str)
return data.get('data', {}).get('rateList', [])商品ID从网址 id=xxxx 获取,cookie提取方法之前写过,这里不重复了。
六、说明与扩展
看到这里,手动复制商品ID再填进去,确实有点麻烦。
但本文的核心目的是带你走通一条完整的逆向分析路径——从定位加密参数、分析算法、到用Python复现并成功采集数据。至于后续的批量采集、数据存储、自动化调度,这些属于锦上添花的扩展功能,留给读者自己去探索。
如果你想让这个爬虫更完善,可以从以下几个方向入手:
- 自动采集:从商品列表页批量提取商品ID,自动轮询采集
- 翻页爬取:循环请求多页评论,爬完所有数据
- 数据存储:导出为 CSV / Excel,或写入 MySQL、MongoDB
- 反爬对抗:增加代理IP轮换、随机延时、UA池
- 异常处理:加入重试机制、日志记录和告警
把这些扩展实现一遍,这套爬虫就不再是一个Demo,而是一个能真正投入使用的采集工具。动手写一遍,比我把所有代码写完更有价值。




